AI systems based on Large Language Models are becoming increasingly complex, posing significant testing challenges.
This article shows how our engine can uncover 10x more system failures compared to standard benchmarking methods.
Setup
Our experiment stress-tests a simple Retrieval-Augmented Generation (RAG) system using 200 document chunks, powered by the GPT-4o model. We chose this test for three key reasons:
- Testing RAG across multiple documents is very time-consuming, and current methods lack reliability
- This scenario is compact enough for effective demonstration (n_docs=200, n_agents=1)
- The ground truth is contained within the document context, enabling our engine to perform optimal searches
We selected the medical domain for our tests — a field where copilot errors are unacceptable.
Metrics under evaluation: context precision, context recall, faithfulness, answer correctness.
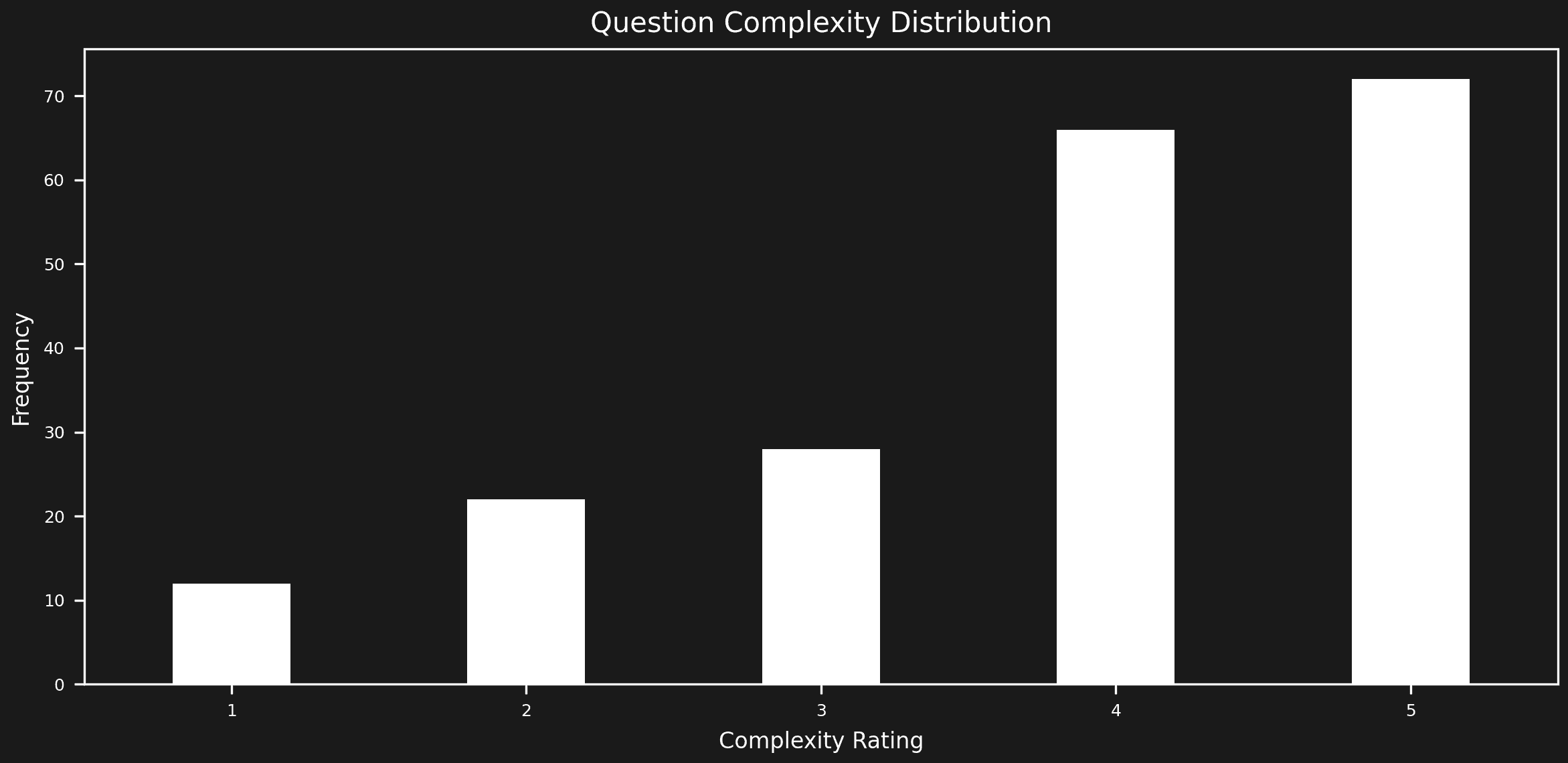
Dataset Analysis
We begin by assessing the assistant with established market solutions for evaluation. First, we use our engine to analyze the evaluation dataset distributions. Unfortunately, synthetic generated datasets often lack balance in their testing space, which we aim to identify and address.
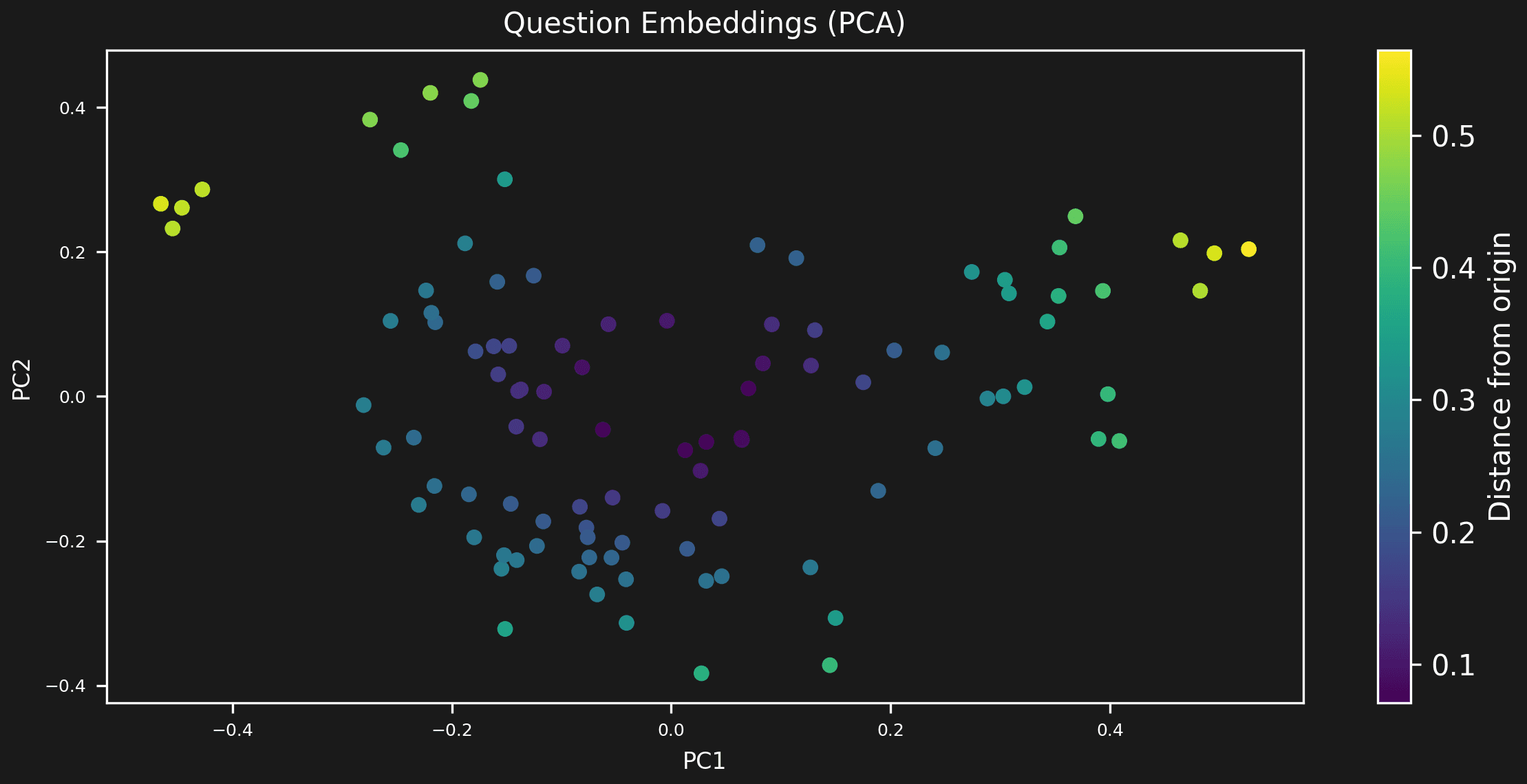
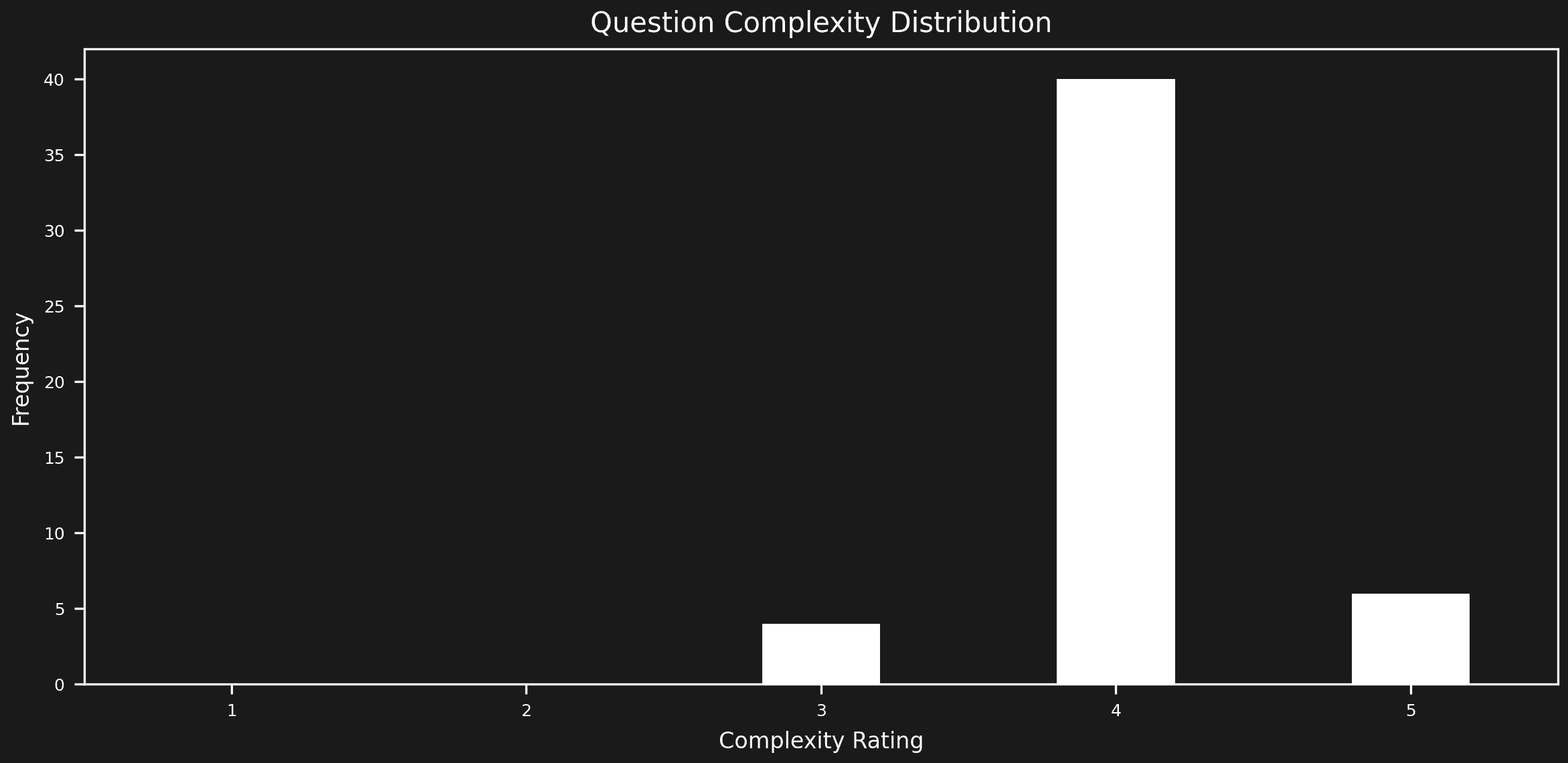
Our preliminary analysis, prior to test execution, has uncovered several dataset issues:
- Uneven distribution of document chunk usage
- Imbalance in query complexity
- Potential for optimizing the embeddings test space distribution
Now, let's examine the test results to identify any strange patterns.
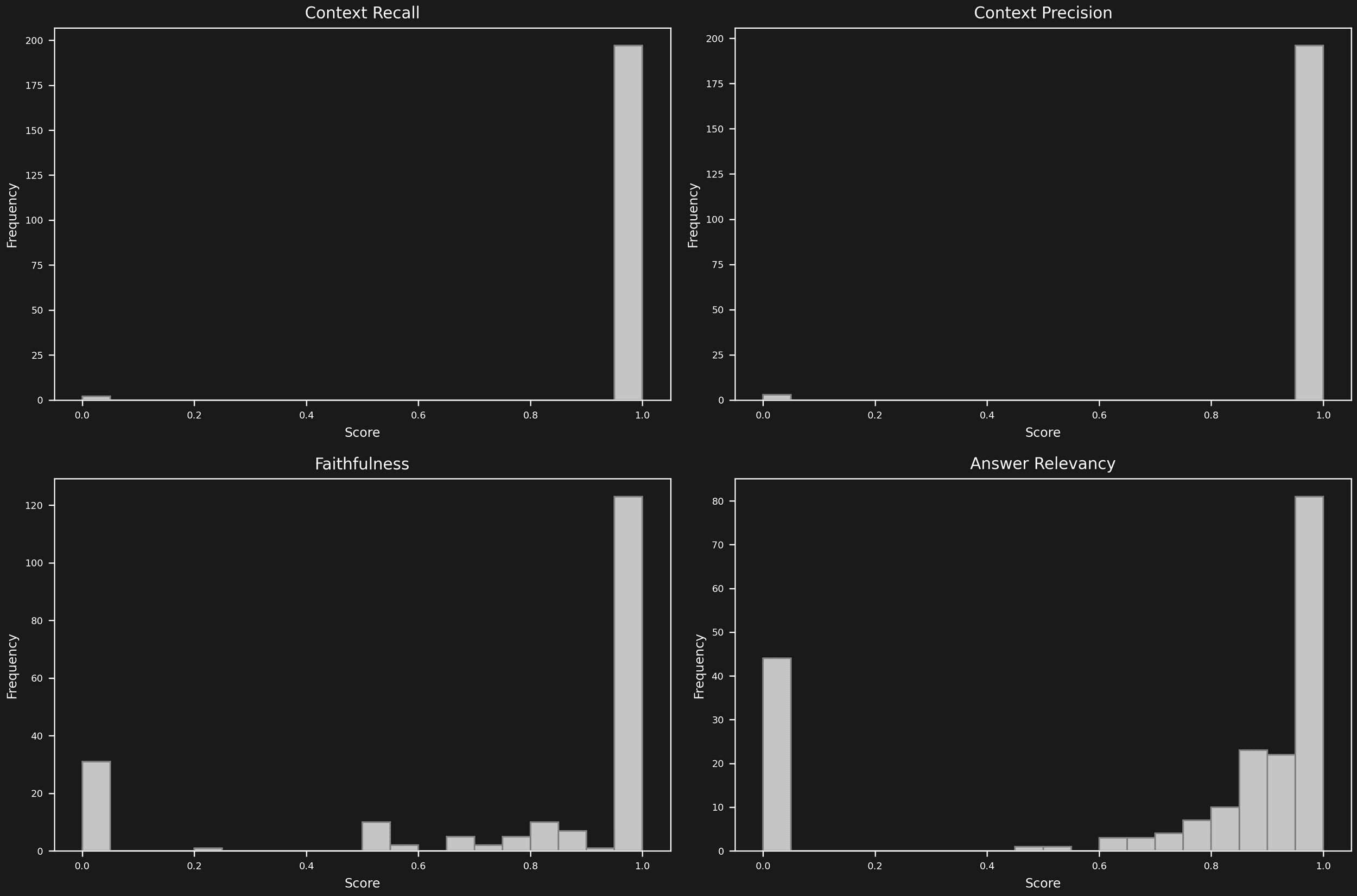
Initial analysis reveals minimal context-related issues. The OpenAI model is performing efficiently, allowing us to concentrate our efforts on improving answer correctness and evolving the dataset.
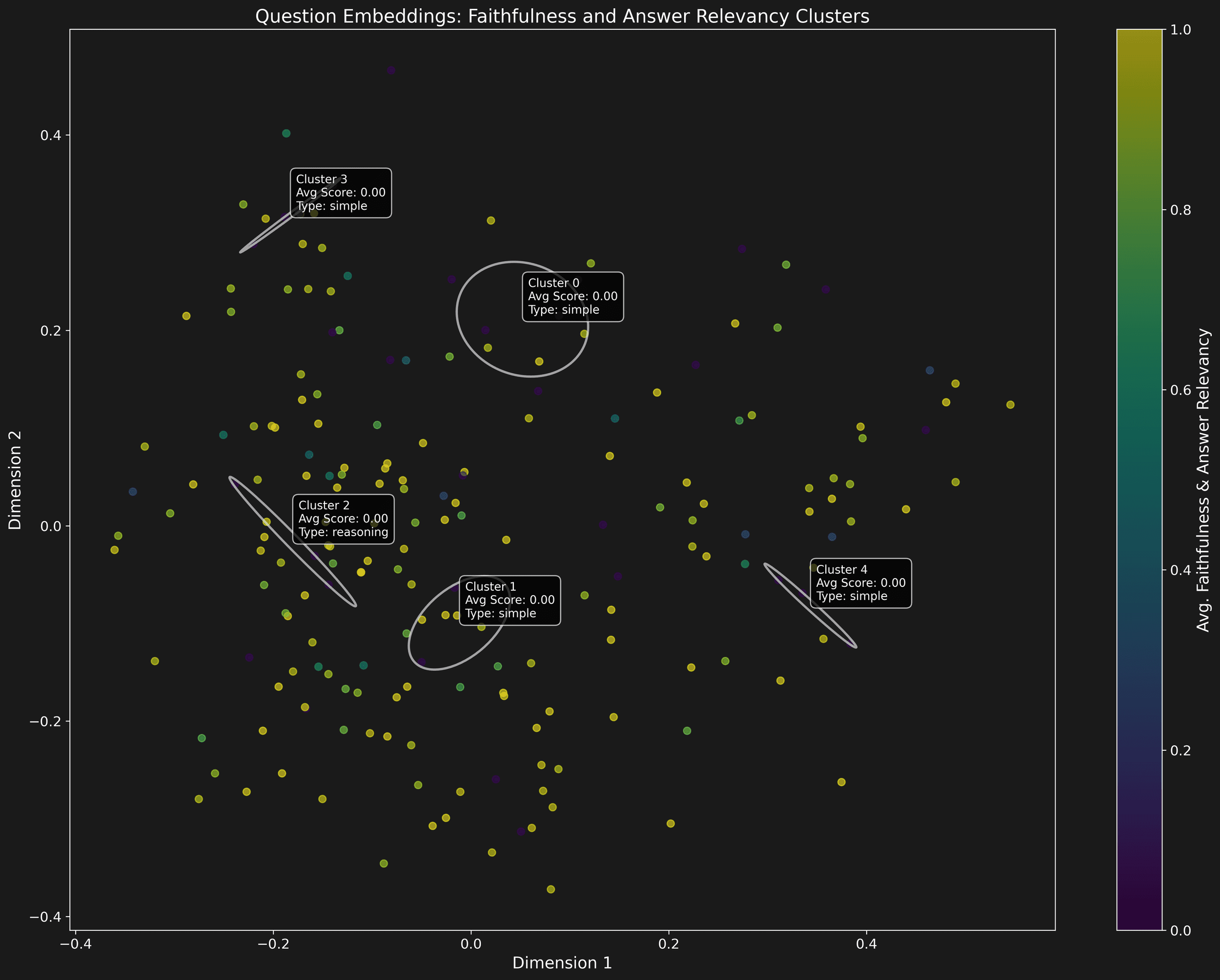
Our engine has identified and clustered the primary blind spots in the model's responses. We've normalized the unbalanced dataset ratio to precisely pinpoint the main issues per dataset unit. This analysis phase sets the stage for our evolution cycle.
Evolution
The engine extracts features from keywords in questions that stumped the model. It generates a new synthetic test space by shuffling and masking these keywords and their neighbors, expanding our evaluation scope.
The evaluation space has undergone a great transformation after just one iteration, driven by key improvements in dataset balance, targeted enhancement of faulty areas, refined feature extraction, and optimized neighbor search.
We set an evolution budget of 100 iterations (i=100) to explore the potential:
E(i) = Σ (Cₖ / Eₖ) · log₂(1 + Kₖ)
where:
Cₖ = cluster growth at iteration k
Eₖ = error units at iteration k
Kₖ = number of keyword clusters
i = iteration number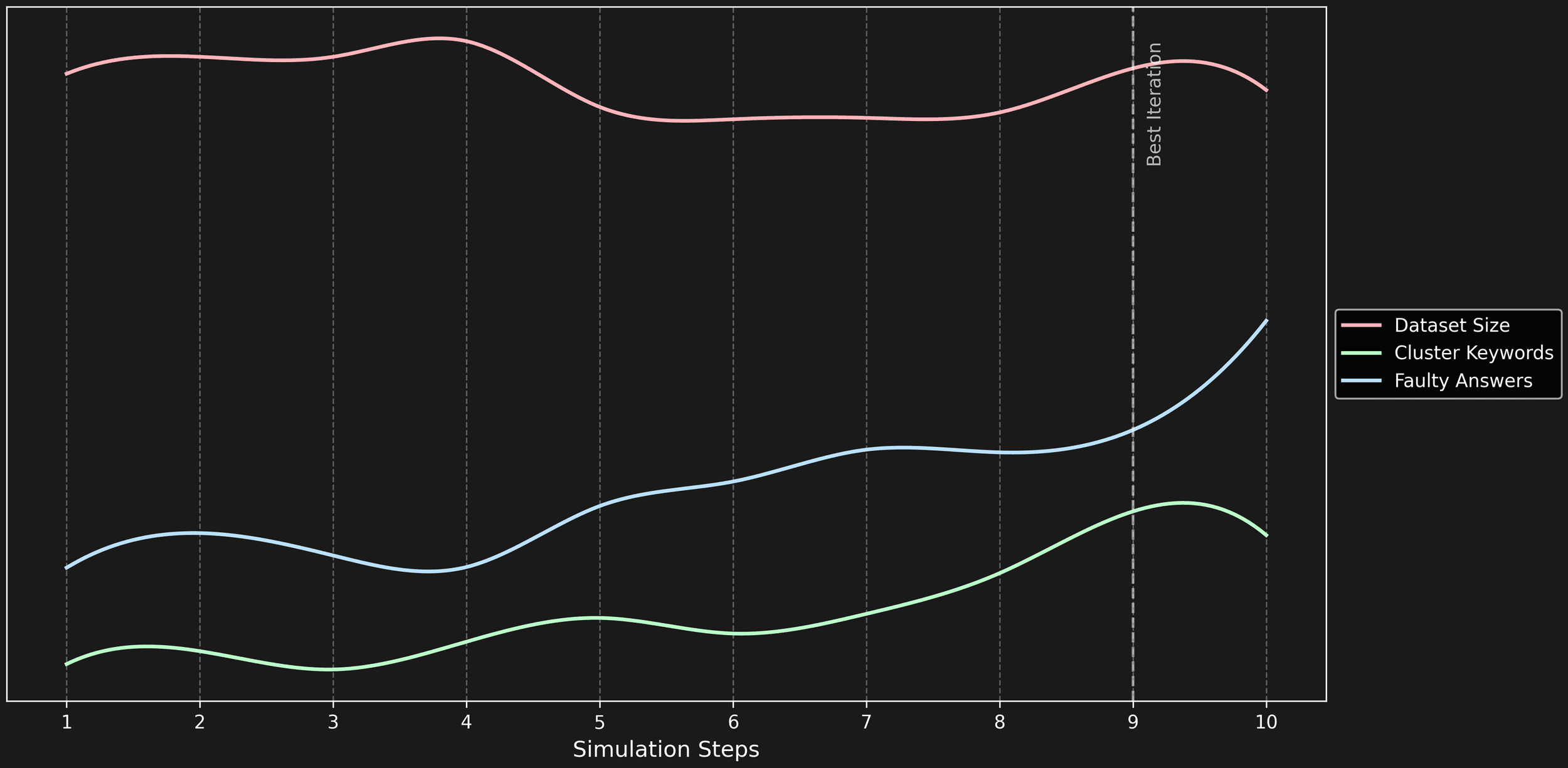
The evolution expanded our testing space dynamically, scaling both clusters and faulty answers effectively.
Cluster keyword growth outweighs error unit increases in importance — it broadens test coverage to new topics, while errors can accumulate within familiar areas.
Our engine achieved a 10x increase in keyword clusters over few iterations, revealing unexpected AI system weaknesses.
This progress in automatic failure discovery for AI systems is promising, but it's just the beginning. We're committed to further advancing this technology, pushing towards more comprehensive AI testing and reliability.